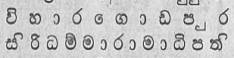Difficulties Relating to the Current Software
Many Asian languages such as Arabic, Chinese, Japanese, and Korean already have character allocation tables. At present, neither Sinhala nor Tamil can progress in the Information Technology sector due to the lack of efficient and sensible character allocation tables. To efficiently use Sinhala and Tamil characters on a QWERTY keyboard, a methodical, logical and easy translation needs to be carried out from Roman characters to Sinhala and Tamil characters: a task usually achieved via a character allocation table. However, this simple translation is hampered when the individual characters are broken into parts (glyphs) and assign to QWERTY keyboard.
As the method of assignment of glyphs differ from one software to the other, it leads to incomprehensibility of text composed on different software. For example, for a document composed with software X using font type AB, the document must also be read on an application running SoftwareX using font type AB. Otherwise, a character "
![]() " used in one software would be reproduced as 'éú§¨' in another. Similarly, key in methods would encounter the same obstacles. There is also a limitation of the usage of characters. Uncommon characters have been discarded. A user is therefore restricted to individual systems and unable to use different types of software. This is a direct result of existing software for Sinhala and Tamil having fixed parameters comprised by a fixed set of font(s) predetermined by the software developers.
" used in one software would be reproduced as 'éú§¨' in another. Similarly, key in methods would encounter the same obstacles. There is also a limitation of the usage of characters. Uncommon characters have been discarded. A user is therefore restricted to individual systems and unable to use different types of software. This is a direct result of existing software for Sinhala and Tamil having fixed parameters comprised by a fixed set of font(s) predetermined by the software developers.
Two different keyboard layouts are used to identify these broken individual characters. This difficulty is particularly acute when confronted with words with many characters and different combinations as shown in the Figure below. Nevertheless, existing software solely uses glyphs to construct a complete character. However, if character allocation comprised of glyphs, modern technology such as Optical Character Readers (OCR) [6] will not be able to identify all these glyphs correctly and construct all individual characters.